An In-Depth Analysis Of ChatGPT’s Architecture: How It Differs From Other Language Models

In November 2022, ChatGPT was released by the OpenAI team and has since enchanted the world.
Training on a large volume of data, ChatGPT can generate content, write essays, code writing, code debugging, and so on.
Did you ever wonder how ChatGPT was able to accomplish these things?
This blog presents you with a granular view of ChatGPTs and how it contrasts with other language models.
So, let’s get started. But before that, first, get familiar with what language models are, what these language models can do, and how ChatGPT language models stack up against others.
What is a Language Model?
The Language Model (LM) is a machine learning tool that predicts the probability of word sequences based on historical language data. A language model is a foundation for other technology-based language disciplines, such as chatbots and conversational AI.
This model can be used for various applications, such as writing original text, predicting the next appearance of a word, recognizing handwriting, and understanding speech.
The development of language models can take many forms. Some have shallow language learning and processing skills, meaning they have limited ability to process language. Those with deep learning and processing abilities can comprehend and process complex language.
Taking a look at the ChatGPT is based on the GPT-3 language model-backed AI research company named OpenAI.
Starting from the ground, GPT-3 stands for the Generative Pre-Trained Transformer. This model is trained using excess data from the internet to generate the most useful responses.
The GPT-3 language structure allows you to create anything that uses a language structure, including answering questions, writing essays, summarizing text, translating languages, and even writing programs.
GPT-3 has been called the best AI ever produced thanks to its language-producing abilities, which makes ChatGPT so impressive.
Let’s get familiar with the ChatGPT architecture to learn how GPT-3 language models work and take the world by storm.
Analysis of ChatGPT Architecture
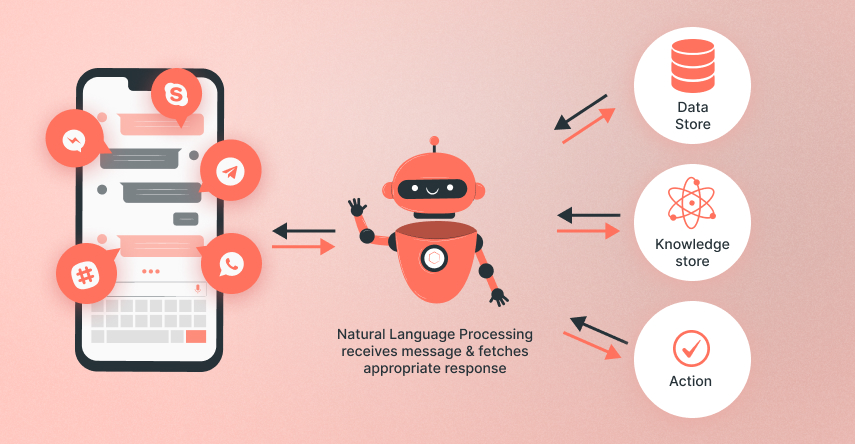
Following is a schematic of ChatGPT’s architecture:
Contextualizing User Request
Taking into account the user’s context and responding appropriately to their needs is what ChatGPT excels. A large part of ChatGPT’s functionality depends on Natural Language Processing (NLP) and Natural Language Understanding (NLU).
NLP engines can analyze the users’ language for meaning and then convert that data into structured input so that the system can process the data. The NLP capabilities are driven by machine learning algorithms that identify the user’s intentions.
With NLU, machines become smarter. By doing so, the machines can understand the data better. Understanding the context, semantics, syntax, intent, and sentiment of the text illuminates the meaning of data that can then be processed appropriately by the machine.
A Scale-Up Approach to Learning
By learning from the data, ChatGPT can serve the user more effectively. As part of OpenAI’s training effort, ChatGPT was provided with a large amount of data collected from various sources, including books, articles, and websites. Whenever a change occurs in the available data, ChatGPT will update itself automatically to become more adaptable to change in the future.
Omni-Channel Capabilities
Stellar omnichannel capabilities drive ChatGPT. Benefiting from these capabilities, ChaTGPT can be worked in different ways, by serving the role of the content creator, working as a virtual support system for your eCommerce businesses, and so on.
What are the Limitations of GPT-3?
Using GPT-3 as the backbone, ChatGPT has provided remarkable results across a wide range of industries with its impressive capabilities. The technology, however, is in its infancy. Therefore it has a huge number of limitations as well.
Whenever a given topic is discussed, GPT-3 must be able to scan the entire internet in nanoseconds for references and patterns. Based on analyzing billions of web pages containing previously published text on the internet, the model generates mathematically and logically plausible words in response to the input. Nevertheless, GPT-3 has no internal representation of what these words mean in their semantic sense. It does not have a semantically grounded model of the world or of the topics it discusses, so GPT-3 only operates based on statistical computations and does not understand the content of input and output texts.
In other words, when asked to write content that differs from the corpus of texts on which it has been trained, the GPT-3 model will have difficulty doing so.
Moreover, GPT-3 is prone to algorithm bias, another significant drawback. The ChatGPT is known to be biased toward certain demographics, including gender, race, and religion.
What are the Different Language Models?
Besides OpenAI’s GPT-3, a few other language modes are also available in the market such as Google’s BERT, Microsoft’s Transformer, Cohere, and Stable Diffusion. Their brief description is as follows:
Google’s BERT
Moreover, Google is working on implementing its language model to maintain itself in a world where AI drives everything.
BERT stands for Bidirectional Encoder Representations from Transformers. This feature works on a neural network and enables Google to learn about users’ search intentions and the contents indexed by its search engine. As a pre-training model for natural language processing, BERT trains on curated data sets (such as Wikipedia).
Microsoft’s Transformer
Microsoft’s Transformer is a deep neural network used to perform natural language processing through a speech recognition algorithm. A self-attention mechanism improves the model’s capabilities by learning from data over time.
With minimal training, Microsoft uses Transformer Networks to answer image questions. Unified VLP models can be trained to understand concepts associated with scenic images.
Cohere
Cohere gives you easy access to advanced Large Language Models and Natural Language Processing tools. With Cohere, users can train massive language models customized to their needs and trained on their data through a simple API.
Stable Diffusion
Stable Diffusion is a text-to-image model sweeping the world by storm due to its deep-learning capabilities. A machine learning algorithm can produce images corresponding to input text prompts. Even the strongest noise can be effectively removed from data using a variant of the latent Diffusion Model.
BERT, Transformer, Cohere, Stable Diffusion, and GPT-3: How Do They Differ?
GPT is not the only language model that has created a lot of hype. Language models have a wide range of abilities that allow them to accomplish much. However, they aren’t suitable for every application, especially when it comes to real-world business scenarios.
When it was released in the market, GPT-3 received a positive response that none of the other language models could achieve. Trained on a massive amount of data, GPT-3 is more capable of producing human-like outcomes.
